Building a Data-Driven Email feature for the kDS Data Source Discovery App
by DL Keeshin
December 29, 2025

In my previous post about deployment automation, I explored how we transformed infrastructure provisioning from days of manual work into a 30-minute automated process. Today, I want to share another critical component of the kDS Data Source Discovery App: the enterprise email invitation feature that sends personalized interview requests while maintaining database integrity, security, and full auditability.
Building an email solution seems straightforward—until you need to track delivery status, handle failures gracefully, prevent duplicate sends during concurrent operations, and maintain a complete audit trail for compliance. What started as "just send some emails" evolved into a sophisticated staged architecture with stored procedures, UUID-based tracking, and database-driven templates. Here's why.
The Challenge: Email at Scale with Full Accountability
The kDS Discovery App conducts structured interviews with organizational stakeholders to capture tribal knowledge about data systems. A typical deployment might need to send hundreds of interview invitations across multiple departments, each with:
- Unique authentication tokens for secure access
- Personalized content based on role and business function
- Expiration dates for security compliance
- Full tracking of delivery status
- Retry capability for failed deliveries
- Prevention of duplicate sends
The traditional approach—generating emails on the fly and hoping for the best—wouldn't meet enterprise requirements for auditability, reliability, and data integrity. We needed better.
Architectural Decision: Staged Processing
The core insight driving our design was separating intent to send from actual delivery. This led to a two-stage architecture:
Stage 1: Interview Invitation Staging (stage.interview_invite)
Purpose: Queue for pending email deliveries
What it contains:
- Invitation metadata (interview ID, respondent ID, token)
- Expiration timestamps for security
- Source tracking (how the invitation was created)
- Creation audit fields (who, when)
Key characteristic: Records exist here until successfully delivered, enabling automatic retry of failed sends
Database schema:
CREATE TABLE stage.interview_invite (
invite_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
interview_id UUID NOT NULL,
respondent_id UUID NOT NULL,
token_ UUID NOT NULL,
invite_date TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
expires_at TIMESTAMPTZ NOT NULL,
source_ VARCHAR(100) DEFAULT 'email_system'
);Stage 2: Sent Invitations (interview.invite)
Purpose: Permanent record of successfully delivered invitations
What it tracks:
- Complete delivery history
- Email job association (which batch sent this)
- Moved from staging after confirmed delivery
- Permanent audit trail
Key characteristic: Records only appear here after SMTP confirms delivery and database transaction commits
Workflow integration:
-- Atomic move operation
CALL stage.up_move_invite_to_sent(
p_stage_invite_id := invite_uuid,
p_job_id := job_uuid,
p_created_by := 'email_system'
);This staged architecture provides several critical advantages: automatic retry capability (failed deliveries remain in staging), idempotent operations (re-running the send process won't create duplicates), and complete auditability (every state change is tracked).
UUID Architecture: Why Global Identifiers Matter
Early in development, we used integer sequences for primary keys—a common pattern in traditional database design. However, the distributed nature of email operations (background workers, concurrent jobs, external SMTP services) revealed the limitations of sequential IDs.
The Problem with SERIAL IDs
Sequential integer IDs create coupling between database operations and business logic. When tracking email jobs across multiple tables, systems, and time zones, you need identifiers that are:
- Globally unique without database coordination
- Generated independently by application code
- Meaningful across systems (logs, emails, API calls)
- Collision-resistant during concurrent operations
The UUID architecture enables powerful debugging capabilities. When an email fails, we can trace the exact invitation across staging tables, job logs, failure records, and application logs using a single globally unique identifier—without complex joins or ambiguous references.
Stored Procedures: Database-Enforced Business Logic
One of our most important architectural decisions was implementing core email workflow operations as PostgreSQL stored procedures rather than application-layer business logic.
Why Stored Procedures?
Email operations require transactional integrity across multiple tables. When an email sends successfully, we must atomically:
- Remove the invitation from staging
- Insert it into the permanent sent table
- Update job statistics
- Maintain referential integrity
Implementing this in application code risks partial failures, race conditions, and data inconsistencies. Stored procedures provide database-enforced atomicity.
Core Email Workflow Procedures
stage.up_start_email_job
Initializes a new email send job with configuration and tracking metadata.
CALL stage.up_start_email_job(
p_job_id := job_uuid,
p_total_count := 50,
p_smtp_server := 'mail.example.com',
p_from_email := '[email protected]',
p_batch_count := 10,
p_batch_delay := 5
);stage.up_move_invite_to_sent
Atomically moves successfully delivered invitation from staging to permanent storage.
CALL stage.up_move_invite_to_sent(
p_stage_invite_id := invite_uuid,
p_job_id := job_uuid,
p_created_by := 'email_worker'
);stage.up_log_email_send_failed
Records delivery failure while preserving invitation in staging for retry.
CALL stage.up_log_email_send_failed(
p_job_id := job_uuid,
p_invite_id := invite_uuid,
p_recipient_email := '[email protected]',
p_error_message := 'SMTP timeout after 30s'
);stage.up_complete_email_job
Marks job completion with final statistics and status.
CALL stage.up_complete_email_job(
p_job_id := job_uuid,
p_sent_count := 48,
p_failed_count := 2,
p_status := 'completed'
);This approach provides several benefits: database-enforced consistency (transactions span multiple tables atomically), reduced network overhead (single procedure call instead of multiple queries), centralized business logic (workflow rules enforced at database level), and simplified application code (Python focuses on SMTP, database handles state management).
Database-Driven Templates: Content Without Code Deployment
Traditional email systems hardcode message templates in application code, requiring full deployment cycles to update email content. We needed the flexibility to refine messaging without touching production servers.
Template Storage Schema
Email templates live in the admin.prompt_setting table as Jinja2 markup:
CREATE TABLE admin.prompt_setting (
name_ VARCHAR(100) PRIMARY KEY,
prompt_text TEXT NOT NULL,
description_ TEXT,
last_updated TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
-- Email templates
INSERT INTO admin.prompt_setting (name_, prompt_text) VALUES
('email_interview_invite_subject',
'Interview Invitation: {{ interview_name }}'),
('email_interview_invite',
'<html><body>
<h2>Dear {{ full_name }},</h2>
<p>You have been invited to participate in:
<strong>{{ interview_name }}</strong></p>
<p><a href="{{ interview_url }}">Start Interview</a></p>
</body></html>');Runtime Template Rendering
The Python application loads templates from the database at send time, not at startup:
def get_prompt_template(prompt_name):
"""Load Jinja2 template from admin.prompt_setting"""
cursor.execute("""
SELECT prompt_text
FROM admin.prompt_setting
WHERE name_ = %s
""", (prompt_name,))
template_text = cursor.fetchone()[0]
environment = jinja2.Environment()
return environment.from_string(template_text)This architecture enables instant template updates through simple SQL statements, A/B testing of messaging variations, role-specific customization, and multi-language support—all without application deployment.
Real-World Challenges and Solutions
Building enterprise email infrastructure exposed several unexpected challenges that required creative solutions.
Challenge 1: PostgreSQL UUID Type Adaptation
Problem: Python's psycopg2 library doesn't automatically convert Python UUID objects to PostgreSQL UUID types, causing can't adapt type 'UUID' errors when calling stored procedures.
Symptom: Emails sent successfully via SMTP, but database updates failed silently, leaving invitations in staging and causing duplicate sends.
Solution: Register a UUID adapter at application startup:
import psycopg2.extensions
# Register UUID adapter for automatic type conversion
psycopg2.extensions.register_adapter(
uuid.UUID,
lambda u: psycopg2.extensions.AsIs(f"'{u}'")
)This single line of code enables seamless UUID handling throughout the application, eliminating the need for manual string conversion at every database call.
Challenge 2: Concurrent Job Race Conditions
Problem: Multiple users (or multiple button clicks) could start simultaneous email jobs, causing duplicate sends before database updates complete.
Manifestation: Same invitation sent 3-4 times within seconds as concurrent jobs all query staging and find the same pending invitations.
Solution: Implement job state checking and UI safeguards:
// Disable send button immediately on click
document.getElementById('send-btn').disabled = true;
// Check for running jobs before starting new one
SELECT COUNT(*) FROM stage.email_job
WHERE status_ = 'running'
AND started_at >= CURRENT_TIMESTAMP - INTERVAL '1 hour';Future enhancement: Database-level job locking using a single-row lock table to enforce mutual exclusion at the database layer.
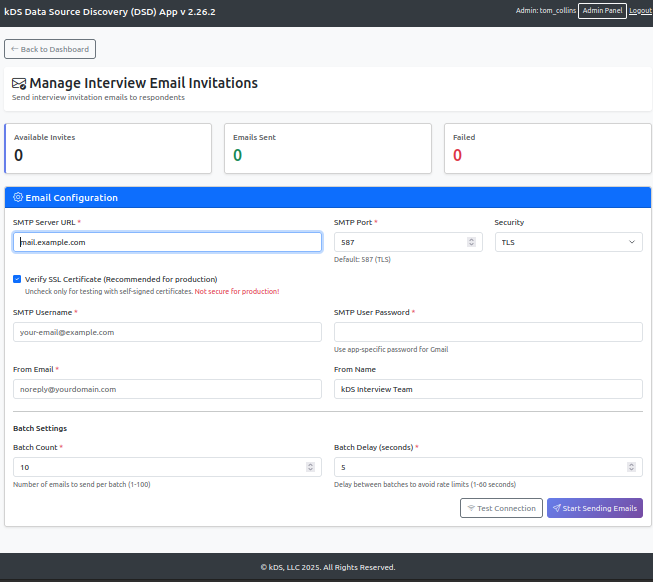
Complete Email Workflow
The end-to-end process demonstrates how all components integrate:
| Step | Component | Action | Database Operation |
|---|---|---|---|
| 1 | Admin UI | User clicks "Start Sending Emails" | Generate job UUID |
| 2 | Email Worker | Query pending invitations | SELECT * FROM stage.interview_invite |
| 3 | Database | Initialize job tracking | CALL stage.up_start_email_job(...) |
| 4 | Template Engine | Load email templates | SELECT prompt_text FROM admin.prompt_setting |
| 5 | Jinja2 | Render personalized content | N/A (in-memory) |
| 6 | SMTP Client | Send email batch (10 emails) | N/A (external SMTP) |
| 7a | Success Handler | Email delivered successfully | CALL stage.up_move_invite_to_sent(...) |
| 7b | Failure Handler | Email failed to send | CALL stage.up_log_email_send_failed(...) |
| 8 | Batch Controller | Wait 5 seconds between batches | N/A (rate limiting) |
| 9 | Job Completion | Mark job complete | CALL stage.up_complete_email_job(...) |
| 10 | Admin UI | Display final statistics | SELECT * FROM stage.vw_email_job |
Monitoring and Observability
Enterprise email operations require comprehensive monitoring. We implemented several database views for real-time observability:
-- Active email jobs
CREATE VIEW stage.vw_email_job AS
SELECT
job_id,
started_at,
completed_at,
total_count,
sent_count,
failed_count,
status_,
smtp_server,
from_email
FROM stage.email_job
ORDER BY started_at DESC;
-- Failed deliveries requiring retry
CREATE VIEW stage.vw_email_send_failed AS
SELECT
f.failed_id,
f.job_id,
f.invite_id,
f.recipient_email,
f.interview_name_,
f.error_message,
f.attempt_date,
i.expires_at
FROM stage.email_send_failed f
LEFT JOIN stage.interview_invite i ON i.invite_id = f.invite_id
WHERE i.expires_at >= CURRENT_TIMESTAMP
ORDER BY f.attempt_date DESC;These views power the admin dashboard, providing instant visibility into email operations without complex application-layer reporting logic.
Lessons Learned
Start with Database Constraints
Implementing workflow logic as stored procedures and database constraints caught bugs that would have manifested as data corruption in production. The database enforces correctness; the application implements policy.
UUIDs Simplify Distributed Systems
The migration from sequential IDs to UUIDs eliminated entire classes of bugs related to ID generation, coordination, and collision. The small storage overhead (16 bytes vs 4 bytes) is negligible compared to the architectural simplification.
Template Flexibility Matters
Storing email templates in the database rather than code proved invaluable during beta testing. We refined messaging, fixed typos, and A/B tested subject lines without touching production servers or coordinating deployments.
Race Conditions Hide Until Production
Concurrent email job execution worked perfectly in testing but immediately caused duplicate sends in production when multiple admins accessed the system simultaneously. Database-level locking will be added in the next release.
Future Enhancements
The email system provides a solid foundation, but several enhancements are planned:
- Database-level job locking: Prevent concurrent jobs at the database layer using mutual exclusion locks
- Exponential backoff retry: Automatically retry failed deliveries with increasing delays
- Email scheduling: Queue invitations for future delivery at optimal times
- Multi-language templates: Leverage database-driven templates for internationalization
- Webhook notifications: Alert administrators of delivery failures or completion
- Enhanced analytics: Delivery rate trends, open tracking (with privacy controls), and engagement metrics
Try It Yourself
The kDS Discovery App email solution demonstrates that enterprise-grade reliability doesn't require complex infrastructure—just thoughtful architecture and attention to edge cases. The combination of staged processing, stored procedures, UUID tracking, and database-driven templates creates a robust foundation for mission-critical email operations.
If you're interested in experiencing this system firsthand, our beta program provides complete access to the kDS Discovery platform, including the email infrastructure detailed in this post. Beta participants receive:
- Full deployment automation (as described in our deployment automation post
- Complete email system with template customization
- Database schema documentation and query examples
- Ongoing support and feature updates
Reach out at talk2us@keeshinds.com to learn more about participating.
Building reliable email infrastructure taught us that the seemingly simple problems often hide the most complexity. UUID type adaptation and race conditions aren't glamorous topics, but solving them correctly makes the difference between a system that works in demos and one that works in production.
The journey from "just send some emails" to enterprise-grade email infrastructure reinforces a lesson we see repeatedly in software development: the hard part isn't making it work once—it's making it work reliably, at scale, with complete auditability. The staged architecture, stored procedures, and database-driven templates we've built for kDS Discovery provide exactly that foundation.
HAPPY HOLIDAYS, HAVE A WONDERFUL 2026!
Thank you for stopping by.